An Introduction to Big-O, Big-Omega, and Big-Theta
Why Use This?
Any program can be represented as a function, f(n), where each term is some type of action. For example, f(n) = n² + 5n + 4 represents the following:
for (int i = 0; i < n; i++) { // O(n)
for (int j = 0; j < n; j++) { // O(n), makes this whole loop O(n^2)
}
}for (int i = 0; i < n; i++) { // O(n)
}int i = 1; // O(1)
i += 1; // O(1)
i += 1; // O(1)return i; // O(1)
By representing our program as a function, we can analyze it and see how fast it runs in a best, worst, and average-case scenario. By doing this we are able to avoid any external factors (i.e. testing a program on a new computer may be faster than testing on an older one).
The following article will give the definition of Big-O, Big-Omega, and Big-Theta as well as how to derive them (examples provided).
Note: I will be using “program” and “function” interchangeable throughout as functions can represent programs.
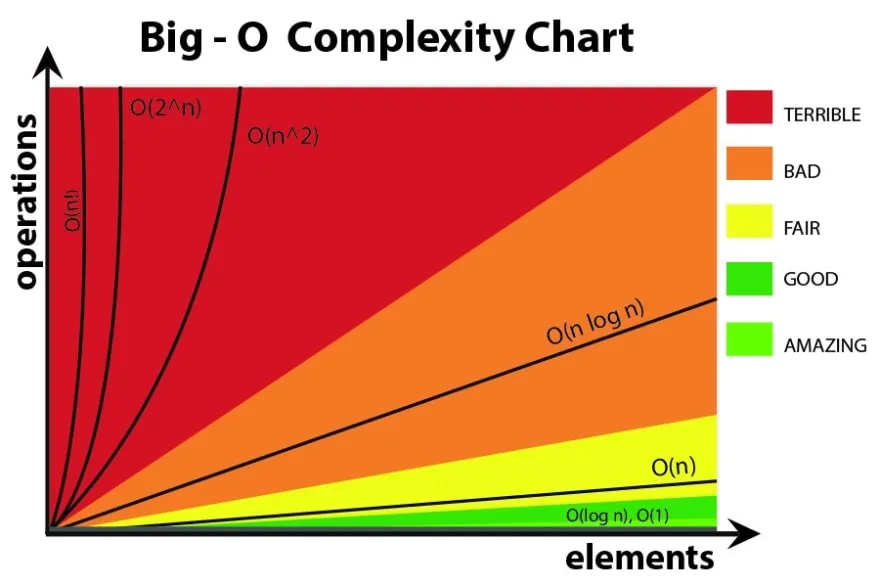
Common Runtimes
While being able to derive more exact runtimes can help when understanding specific algorithms, many times you should be able to classify a program using one of the following(sorted from fastest to longest). Let n be our input size:
- (1) is known as constant time. Here, the size of n does not impact speed.
- (log_c(n)) is known as logarithmic time. Here, our runtime changes with respect to the log-base-c of n)
- (n) is known as linear time. Here, our runtime changes directly with respect to n.
- (n log(n)) is known as superlinear time. Here, our runtime is slower than linear, but not enough to be polynomial.
- (n^c) is known as polynomial time. Here, our runtime has slowed down to being dependent on the c’th degree of n.
- (c^n) is known as exponential time. Here, our runtime has become proportional to a value, c, raised to our input size.Very slow and explosive.
- (n!) is known as factorial time. Our runtime is now very slow, being equivalent to the factorial of our input size.
Big-O
Summary:
Big-O is known as the worst-case scenario of a program. Given a very large input (think infinite), the Big-O will give us an idea of how slow our algorithm may run.
Understanding the Math:
For a function, f(n), we can say that it is Big-O g(n) (denoted O(g(n)), given the following:
- k is a positive number that we multiply g(n) by so it is greater than or equal to f(n)
- n is the inputs for our functions (Note: You will want to choose n such that g(n) will eventually be greater than or equal to f(n)).
- f(n) is our initial function that represents our program’s runtime
- g(n) is a function we are bounding f(n) above by and saying “g(n), when modified by k, will always be greater than or equal to f(n) from a point on”
Since g(n) will always be greater than or equal to f(n), we can call g(n) an upper bound of f(n) since we know that f(n) will never result in a value greater than g(n).
Let’s go through a few examples:
- f(n) = 50n³ + 30nlog(n) + 30n. We can prove that this function is O(n³) by doing the following:
2. f(n) = 60n + 20log(n). I’ll show you how this function is O(n) and more.
The second example shows how a function can actually have an infinite amount of Big-O’s, as we can merely increase the degree of the function. The point of Big-O, however, is to try and find the tightest bound, one that is as close to f(n) as possible.
The Quick Way:
“Do I really have to do this every time I want to derive a function’s Big-O?” Luckily, no. Now that you hopefully have an understanding of how Big-O is derived, there is a quicker method that can be used.
- Drop any constants
- Take note of the highest-order term in the function
Look at the following examples to see this quicker method at work:
- f(n) = 40nlog(n) + 20n + log(n).
Dropping constants, we get f(n) = nlogn(n) = n + log(n). We now see that nlog(n) is the highest-order term. So we can say f(n) is O(nlog(n)). - f(n) = 50n²+30nlog(n)+20.
By doing the same process we get n² as the highest-order term.
So we can say that f(n) is O(n²).
Big-Omega
Summary:
Note: Out of the three methods of analysis presented here, Big-Omega is the least helpful and thus, least. This is because the best-case of a program is not as impactful on runtime as it’s worst-case. However, having a basic understanding of Big-Omega is helpful for knowing Big-Theta.
While Big-O gives us an upper-bound, Big-Omega shows us the lower-bound. Given a large enough input, Big-Omega shows us how fast our algorithm can run (This is it’s best-case scenario).
Understanding the Math:
For a function, f(n), we can say that it is Big-Omega g(n) (denoted Ω(g(n)), given the following:
- k is a positive number that we multiply g(n) by so it is less than or equal to f(n)
- n is the inputs for our functions (Note: You will want to choose n such that g(n) will eventually be less than or equal to f(n)).
- f(n) is our initial function that represents our program’s runtime
- g(n) is a function we are bounding f(n) below by and saying “g(n), when modified by k, will always be less than or equal to f(n) from a point on”
Let’s go through some examples.
- f(n) = 50n³ + 20n² + 10nlog(n) + 30n
2. f(n) = 5n² + 10nlog(n) + 2n + 8log(n)
The Quick Way:
To quickly get the Big-Omega of a function, f(n), one can do a similar process to finding Big-O quickly. Given f(n):
- Drop constants
- Look for the lowest-order term.
Let us look back at the examples we just used to see this method.
- f(n) = 50n³ + 20n² + 10nlog(n) + 30n
Dropping the constants, we get f(n) = n³ + n² + nlog(n) + n. We now see that the lowest-order term is n. This means that f(n) is Ω(n). - f(n) = 5n² + 10nlog(n) + 2n + 8log(n)
By doing the same process we get log(n) as the lowest- order term.
So we can say that f(n) is Ω(n²).
Big-Theta
Summary:
If Big-O refers to our program’s worst case scenario, and Big-Omega refers to our best-case scenario, what does Big-Theta refer to?
Big-Theta is our program’s average-case running time. While Big-O and Big-Theta refer to two polar opposites, Big-Theta is the mean running time of our algorithm.
Understanding the Math:
We are able to represent the Big-Theta of a function, f(n), by referring to it’s Big-O and Big-Omega values. For f(n) to be Big-Theta g(n) (denoted Θ(g(n)), f(n) must be both O(g(n)) and Ω(g(n)).
- k and c are just arbitrary constants we multiply g(n) by to obtain these properties.
- k*g(n) represents the Big-Omega of f(n)
- c*g(n) represents the Big-O of f(n)
Since Big-O and Big-Omega represent upper and lower bounds, respectively, if both of them can be represented by g(n) multiplied by some arbitrary constants, then then we know that f(n) in between these functions. So, on average, f(n) will have a runtime that is also g(n).
Let’s go through some examples:
- f(n) = 50n³ + 20n² + 10nlog(n) + 30n
2. f(n) = 5nlogn(n) + 2n
In Conclusion
Hopefully this read has allowed you to have a clearer understanding on how to analyze algorithms and use Big-O, Big-Omega, and Big-Theta effectively. Below are a few more examples for Big-O, Big-Omega, and Big-Theta.
Further Examples
- Question: f(n) = 30n + 5. Show that f(n) is: Θ(n)
Solution:
- Question: f(n) = 10log(n) + 3. What are the tightest-bounds we can make for O, Ω, and Θ .
Solution: We can prove that f(n) is both O(log(n)) and Ω(log(n)) (While there are other functions that we can use to describe f(n), log(n) is the only one that they share). Since both the Big-O and Big-Omega are the same, we can say f(n) is Θ(log(n)). - f(n) = 30n^n. Is f(n) O(n!)? Ω(n!)?
Solution: Let g(n) = k*n!, where k is some constant.
Given a large amount of input values, f(n)’s output values will be greater than or equal to g(n)’s. This means that f(n) is not O(n!). However, this does prove that it is Ω(n!). - f(n) = 50log(10n² + 30n). Prove the Big-O and Big-Omega for f(n).
Solution:

